SuperInference: A Feedback-Augmented LLM Agent Framework for Complex Reasoning
- Posted on June 05, 2026
- cloud, engineering, AI, agentic, superinference, LLM, research
- By Carlos Camacho
Large Language Models are powerful, but single-shot prompting falls apart when tasks require multi-step reasoning, iterative refinement, and real-world tool usage. SuperInference is an open-source framework that solves this by combining agentic orchestration with information-theoretic principles — giving LLMs the ability to know when and how to iterate.
What is SuperInference?
SuperInference is a feedback-augmented LLM agent framework designed for complex programming tasks and multi-step reasoning. Rather than relying on ad-hoc prompt chaining, it provides a principled, reusable architecture where an AI agent iteratively refines its outputs using execution feedback, maintains an explicit belief state about task progress, and uses mathematically grounded stopping criteria to determine when further reasoning is cost-effective.
The project is fully open-source under the Apache 2.0 license and available at superinference.org.
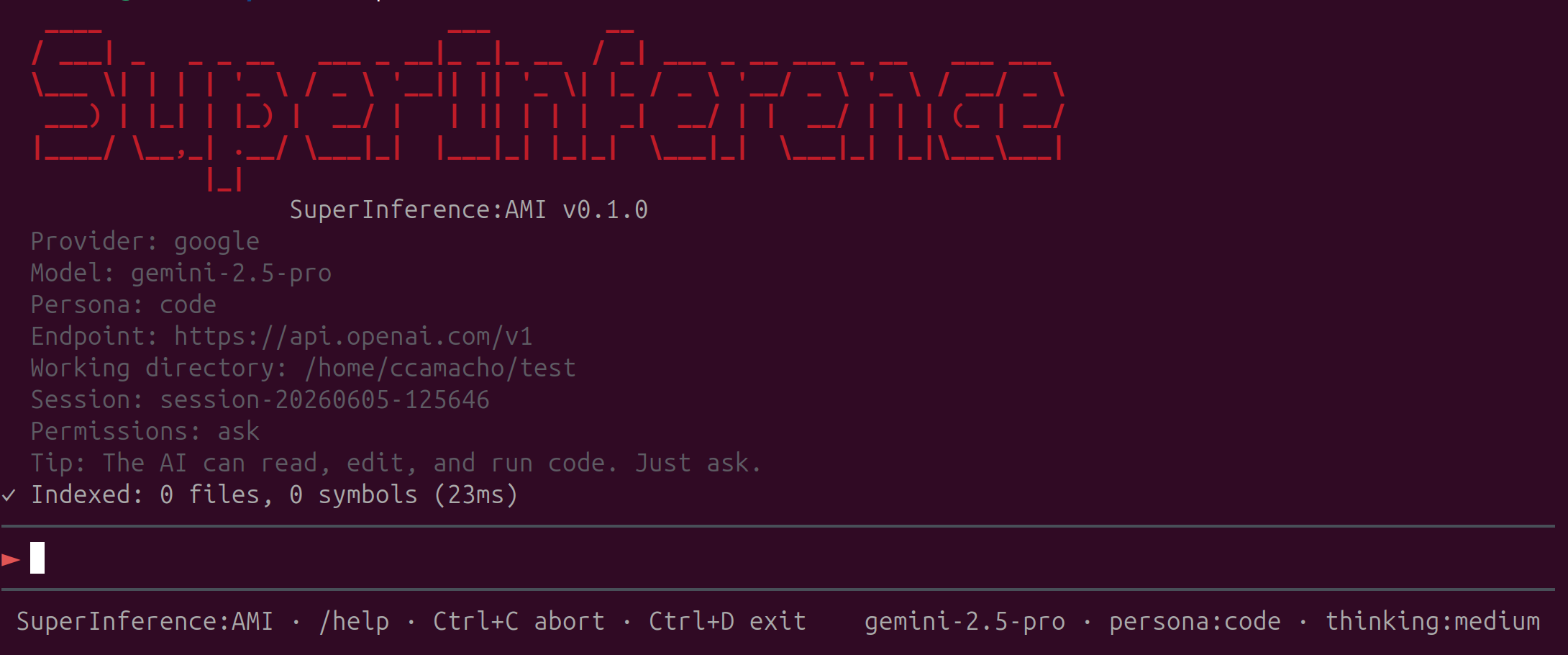
The PRE Loop: Planner-Retriever-Executor
At the heart of SuperInference lies the PRE loop with critic-gated memory — a feedback cycle that mirrors how expert programmers actually work:
- Planner — Maintains a belief state (probability distribution over hidden task states) and fires events when Expected Information Gain (EIG) exceeds a threshold.
- Retriever — Accesses semantic memory through an
embedding-based noisy channel (cosine similarity over
OpenAI’s
text-embedding-3-small). - Executor — Generates candidate actions conditioned on the retrieved context.
- Critic — Evaluates results with explicit error rates (false positive α, false negative β) and gates memory updates so only high-quality artifacts are stored.
- Memory — Stores only critic-approved artifacts, preventing error cascading across iterations.
This creates a closed feedback loop: observations refine beliefs, EIG guides iteration depth, and stopping criteria prevent diminishing returns.
The Math Behind It
SuperInference formalizes agent operation as a Partially Observable Markov Decision Process (POMDP) with:
- A hidden state space S representing task progress, available tools, and unresolved subgoals.
- An observation space O covering critic decisions, execution results, and retrieved context.
- Bayesian belief updates with interpolation rates (λ+ = 0.35 default, 0.70 for strong evidence).
- EIG stopping criteria — iteration stops when expected information gain falls below ε = 0.01.
- Explicit modeling of noisy channels for retrieval imperfections and critic errors.
This mathematical foundation means SuperInference doesn’t just hope additional iterations help — it measures whether they will.
Multi-Provider, Multi-Platform
SuperInference works with virtually any LLM provider:
| Provider | Models |
|---|---|
| OpenAI | GPT-4, GPT-4 Turbo, GPT-4o |
| Gemini 2.5 Pro, Gemini 2.5 Flash | |
| Anthropic | Claude 3 Opus, Sonnet, Haiku |
| Others | DeepSeek, Groq, Mistral, Ollama, OpenRouter |
It ships as a CLI REPL, a VS Code extension (search “AMI - SuperInference” in the marketplace), and an OpenClaw plugin — so it fits into whatever workflow you already have.
16 Built-in Tools
SuperInference comes equipped with tools for real-world
tasks: bash execution, file read/write/edit, grep search,
web fetching, PDF parsing, symbol navigation, code
formatting, and more. Combined with slash commands
(/model, /session, /memory, /cost, /resume,
/compact, and others), it provides a complete interactive
development environment.
Performance: 3.25x Improvement on Hard Tasks
On the DABStep benchmark for complex reasoning:
- Hard tasks: 12.7% → 41.3% accuracy (3.25x improvement)
- Leaderboard rank: 3rd place overall (as of December 2025)
- Most gains are concentrated in the first two refinement rounds (peak 50.7% at round 2 for hard tasks)
- Correctly solved tasks average 1.9 rounds vs. 2.4 for failed tasks — the framework knows when to stop
Getting Started
# Quick install
curl -fsSL https://www.superinference.org/install.sh | bash
Set your API key and you’re ready to go:
export AI_API_KEY="your-key-here"
ami --model gpt-4o
VS Code Extension
SuperInference is also available as a VS Code extension called AMI - SuperInference:
- Open VS Code and go to the Extensions view
(
Ctrl+Shift+X/Cmd+Shift+X). - Search for “AMI” or “SuperInference”.
- Click Install.
- Open the chat panel with
Ctrl+Alt+P(Cmd+Alt+Pon macOS). - Set your API key when prompted.
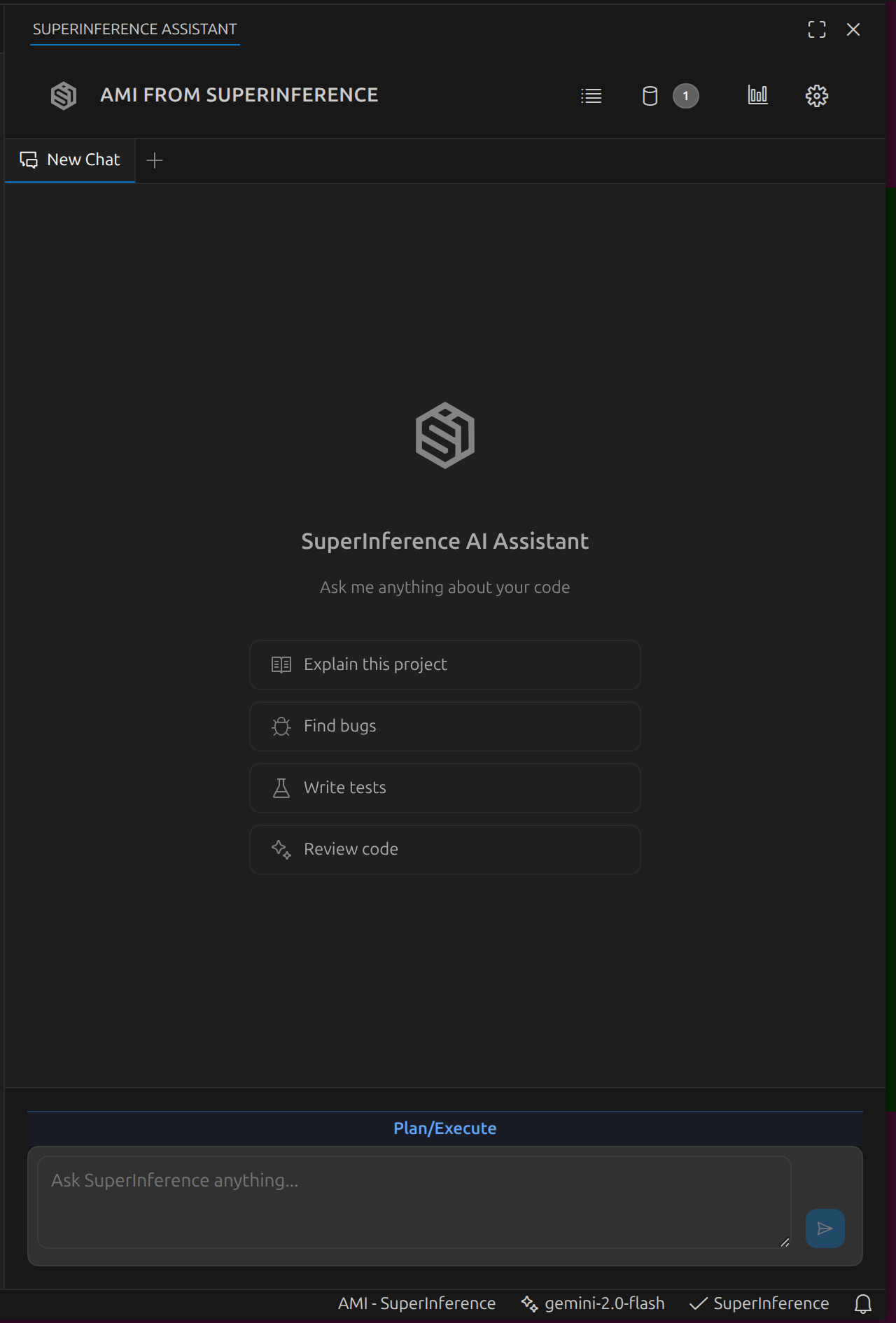
The extension provides inline code lenses above functions
for quick actions (Explain, Fix, Edit, Review, Test,
Optimize) and supports the same slash commands as the CLI
(/model, /session, /memory, /cost, /resume,
/compact).
Demo
Here’s SuperInference in action:
A Fun Example: The Tortilla Paper
To showcase SuperInference’s ability to handle complex, multi-step tasks beyond code, we asked it to write a full research paper on the perfect Spanish tortilla — complete with historical context, culinary science, and regional variations. The result is a fully formatted LaTeX paper that demonstrates how the PRE loop handles iterative document generation.

You can download the full generated paper here: tortilla_paper.pdf
The Research
SuperInference is backed by a peer-reviewed paper WIP authored by Carlos Camacho-González (Red Hat / Universidad Complutense de Madrid), Cristina Catalán-Torrecilla, Luis Llana, Alberto Núñez, and Luis Tomás.
The research was funded through Horizon Europe grant 101093129, Spanish Ministry of Science projects PID2023-149943OB-I00 and PID2021-122215NB-C31, and Madrid region project TEC-2024/COM-235.
Why It Matters
Most LLM agent frameworks treat iteration as an afterthought — retry on failure, chain prompts linearly, or let the user decide when to stop. SuperInference inverts this: iteration is the core mechanism, governed by information theory rather than heuristics. The result is an agent that reliably handles multi-step tasks, knows when to push deeper, and knows when to stop — all without model retraining.
If you’re building with LLMs and need more than single-shot prompting, give SuperInference a look: github.com/superinference | superinference.org
Responses
Want to leave a comment? Visit this post's issue page on GitHub (you'll need a GitHub account. What? Like you already don't have one?!).